Share and deploy your Machine Learning services with Docker
Many resources focus on machine learning algorithms, which are really interesting, yet forget about the end of the cycle.
Many resources focus on machine learning algorithms, which are really interesting, yet forget about the end of the cycle. I would like to emphasize how to easily share and deploy your Machine Learning services thanks to Docker. It enables to ship your source code with all the system and languages dependencies so that it works on all machines.
For that purpose, we are going to train a model on the famous iris flowers dataset and as the goal is to focus on the pipeline, we will not make a deep processing on the data.
TLDR
You can find the whole source code on my Github here.
Training
Source code
Let’s begin with importing our dataset. It contains four features about sepal and petal of flowers, and the related species.
We keep Sepal Length, Sepal Width, Petal Length, Petal Width as features (X) for our model and Species as the target (y) we want to classify.
## Import dataset
logging.info(f"reading {input_path}")
iris = pd.read_csv(input_path)
X = iris.drop("Species", axis=1)
y = iris.Species
# Instantiate PCA
pca = PCA()
# Instantiate LogReg
logistic = SGDClassifier(
loss="log", penalty="l2", max_iter=100, tol=1e-3, random_state=0)Then, we mimic a training pipeline:
- a Principle Component Analysis to reduce the dimensionality of our features that are redundant.
- as our dataset is tiny, the choice of a linear is made with a Logistic Regression.
- finally, a Grid Search to find the best parameters among several possible combinations with a 3 K-fold validation to reduce the importance of how the training data is chosen.
param_grid = {
"pca__n_components": [2, 3],
"logistic__alpha": np.logspace(-4, 4, 5)
}
# Define training pipeline
pipe = Pipeline(steps=[("pca", pca), ("logistic", logistic)])
# Training
logging.info("beginning training")
search = GridSearchCV(
pipe, param_grid, iid=False, cv=3, return_train_score=False)
search.fit(X, y)
print(f"best parameter (CV score = {search.best_score_})")Finally, we save the best estimator from Grid Search and dump our model into a file to persist it.
logging.info("saving best model")
dump(search.best_estimator_, output_path)Dockerfile
It is now time to build the Docker image containing our source code. We start from the official Python 3.6 image. Then, we only copy the requirements.txt from our source code, and install the dependencies, it enables to cache these steps so that we don’t have to download dependencies every time we re-build our image. Finally, we copy the training file and define our entry point. As a consequence, we will just need to give parameters while running the image.
FROM python:3.6
LABEL maintainer="Thomas Legrand"
WORKDIR /app
# install dependencies
COPY requirements.txt /app
RUN pip install -r requirements.Txt
# copy source code
COPY Training.py /app
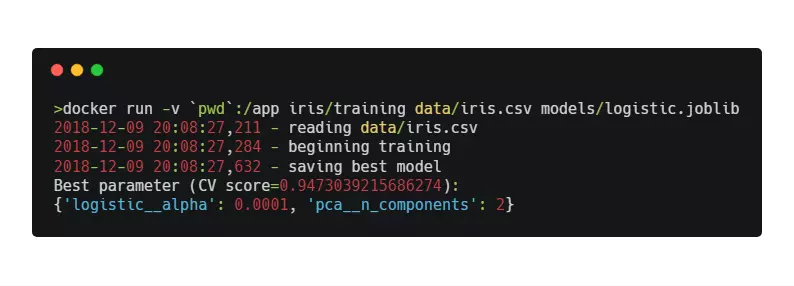
ENTRYPOINT ["python", "Training.py"]We can now finally start to train by providing paths to input CSV file and model output file.

Inference
Source code
Let’s move to the inference part. First, let’s import our trained model, and read the input file we would like to be predicted.
# load classifier
logging.info(f"loading classifier {classifier_path}")
classifier = load(classifier_path)
# load input data
logging.info(f"loading input file {input_path}")
data = pd.read_csv(input_path)As usual, we call the predict method of our loaded model to infer the class given each input.
Dockerfile
The inference Dockerfile is really similar to what we got before. We could also include the dumped model inside to get an all-included image.
The script is called like shown:

Lighter images with Python alpine
The provided default Python image is already quite heavy as it is based on a Linux distribution, but dependencies increase a lot the size of the image.
What you can do is reduce the number of external dependencies you use, or reduce to the minimum the OS size. And here comes Alpine to the rescue: a lightweight Linux distribution containing the minimum required to run a project.
We still need to install system dependencies as Python Data Science libraries are based on some C/C++ and Fortran code, hence the need of gcc and gfortran, and not to mention openblas. I also always add alpine-sdk, containing git, tar, curl for debugging purpose, but you could use build-base for the bare minimum to get a lighter image.
FROM python:3.6-alpine
LABEL=maintainer="Thomas Legrand"
WORKDIR /app
# get system dependencies for python packages
RUN apk update \
&& apk add alpine-sdk gfortran openblas-dev
# install dependencies
COPY requirements.txt /app
RUN pip install -r requirements.Txt
# copy source code
COPY Training.py /app
ENTRYPOINT ["python", "Training.py"]As a matter of comparison, you can see we have reduce our image size by around 25%:

Final words
We have seen how to include Docker into the classical Machine Learning workflow, to separate concern between training and inference. You now have all the tools to share and deploy your services and think of automating the re-training of your model.